Clean code dream

It has been almost a decade after the Clean Code handbook was published describing a set of best practices for producing software that is not only functional, but also designed as easy to understand and adapt as possible. This set of practices has been a conventional wisdom probably for more than 10 years among professional software developers. Some practices and patterns became outdated because of the development tools or hardware evolution and since then were automated and incorporated into static analysis tools, IDEs and right into modern programming languages. Let’s look at the present programming languages from the Clean Code point of view and try to imagine a more advanced language that would help us to produce clean code from the start.
That book was based on good old Java 5, and describes recipes on how to make your code clean. The process of cleaning the code apparently required a lot of manual work to be done. Newer production programming languages emerged in the industry since the book was published in 2008, such as Go (2009), Rust (2010) and Swift (2014). These languages bring a lot of advancements important for Clean Code. To give an example: Go has gofmt; Rust has incorporated memory management best practices; Swift detects a number of rules violations as warnings. Yet we are still far from dealing with all the clean code practices. Even simple things like formatting are not fully settled, so the book stays relevant by and large.
Is “linting” a solution?
To be fair there are good tools doing static analysis (so called “linters”) for most popular programming languages. Those tools are either integrated into IDEs or run from command line, and produce a report on best practices violations in your codebase and usually give an advice about fixing the found problems or even provide automatic fixes.
The problem with this approach is that it requires a number of manual steps, decisions to make with the team and discipline to implement a follow-up process. This might involve meetings with the team on the linting subject, collaboration on a document describing the team’s code style and a set of best practices (with discussions and argues), configuring a linting tool, designing a process to always run this tool (that might involve a CI system setup).
Another problem is that such best practices implementation is very much local to a given project or a team with a flavor lobbied by the technical lead. After jumping to another project or team you might have to unlearn some of (no longer) “best practices”, and adapt to new customs. If the system is not in place, you have to go through the same setup process (with discussions and argues). In some teams who have a more slack and informal point of view on the clean code practices one might have to revert to manual or semi-automatic (facilitated by IDE) code health control on a case by case basis.
Imagine a clean code programming language
I believe that the way forward is to weld more and more of the static analysis directly into programming language infrastructure. When there’s a best practice guideline for a given language that tends to facilitate writing cleaner code in most cases, the language compiler could have a smart compilation warning that is enabled by default, and prevents building of any piece which is not clean. The warning is smart enough to provide an automatic “fix-up” solution to your lines of code, or at least advise a number of alternative fixes.
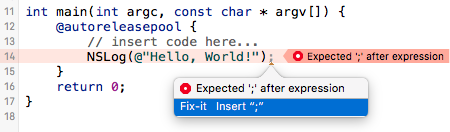
Right off the bat I have to mention that there are different projects and situations in which some rules are not applicable. Thus the warning mechanism must allow suppressing certain warning where the code author explicitly stated so. In addition there might be several “strictness” levels of code cleanness that you can toggle between in order to disable groups of rules. For example, there can be a “prototype” or “startup” strictness level where nasty hacks are allowed, but then the “production” level, where every check is enabled, must be the default.
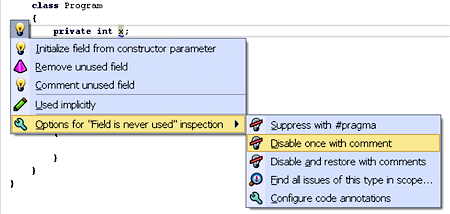
All the clean code rules could be openly discussed by the programming language community. When a consensus about a rule is reached, the rule is implemented and becomes one of the standard warnings enabled by default. No more “holy wars” and frustration - the discussion is over, the decision has been made once and for all. No need to do the initial setup, and no longer you forget to run a linter (before pushing to a CI server with a 1 hour queue) - the checking is fundamentally integrated for everyone.
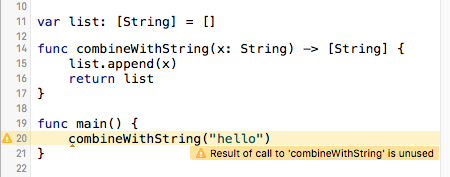
The process of implementing such rules to force the clean code best practices is going on slowly in various programming language communities. A good example would be this Swift warning if a function return value is unused. It is definitely easier to introduce such changes into a new programming language which doesn’t have a lot of legacy dirty code written, but not impossible to have an experimental compiler to an established language, given that the community is open for the code improvement.
Clean code programming language features
Let’s dive in and imagine how to reach that dream goal with concrete ideas and examples.
Clean code style
The mundane code formatting issues raise a lot of code review comments, sometimes wrangles, and waste a lot of time in general. Programmers must pay attention to details, and sometimes they do it extremely well as they are spotting even invisible (and harmless) extra space here and there.
I wish there was a clear and detailed code formatting guide in each programming language ecosystem that everybody agrees upon, and that such guide is a base for a common style checker and code beautifier tool which fixes the code to have the right formatting. That’s what the Go language community did: defined the style once and for all and implemented gofmt code formatting tool. This is already great to have a global policy that everybody respects and a common beautifier tool, but it’s not enough for the clean code programming language. The beautifier logic must be mandatory and integrated into compilation providing warnings and automated code fixes. This ensures that all the code is clean (consistent) in formatting.
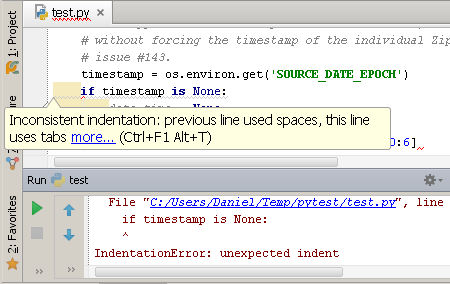
The style guide and formatting rules should be defined up to the finest point, or else it might not work. For example, there’s a code style rule to indent code blocks. In many languages you SHOULD do that for the code to look clean and nice. The Python language specification was the one that said: you MUST do that. It’s great, because now all code blocks everywhere are indented. Unfortunately Python didn’t define how exactly to indent: with tabs, spaces, and how many spaces? Furthermore the Python interpreter was designed to crash at runtime if a mix of indentation symbols was found. Given that “tabs versus spaces” is a never-ending “holy war” (confusion), and that Python didn’t have a mandatory compilation or linting phase, this predictably led to a common source of mistakes. Don’t do it wrong.
Clean code comments
Code comments are a free-form text around the code, or are they not? There are best practices around comments, and it’s possible to automate some of them:
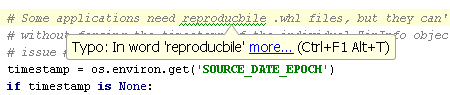
- At a minimum the clean code programming language needs spell-checking and spelling correction.
- The commented-out code should be detected and flagged for deletion.
- Redundant or poorly written comments that bring no value can sometimes be detected.
- “TODO” comments can be processed for sorting and prioritization.
- Software source code license comment blocks on top of the files could be standardized.
Clean naming
Naming is one of the hardest parts of programming, but let’s not close our eyes to this problem. Names can be parsed and analysed to see if they make sense, and if they follow the clean code naming rules. When there’s a violation, a warning is raised by the clean code programming language compiler giving a few better name suggestions. Spend some time to decide on a better name or else you simply won’t get the code into production.
One obvious rule would be that names should be composed of the programming lexicon and normal dictionary English words. “ri” would be unacceptable, but “rowIndex” is just fine.
A further refinement of this rule could be to ban meaningless, overloaded or redundant words as part of the names, like “interface” or “manager”.
A code smell “magic numbers” is related to insufficient naming. It is possible to detect literal constants used in complex non-constant expressions and produce a warning giving a suggestion to extract that literal as a new named constant.
Clean code structure
The clean code structure is partially achieved by minimizing the number of parts (such as lines of code in a function, functions in a class, classes in a module) in order to make each part obvious to understand, and eventually to be able to understand the whole system composition. But we can’t simply “chop” the code up. The code decomposition must be such that each part is forming a cohesive concept: self-contained and integral (at least to some degree). The latter is definitely a harder part left for programmers, but minimizing the number of parts can be assisted by the clean code programming language.
It is a known fact that humans can’t juggle with too many mind concepts at the same time. Something like 5 is often too many. Let’s say there’s a source code file with a class that has 5 functions each of which has 5 lines of logic code (not including the function declaration block). Assuming that the decomposition and naming have been done right, it should be easy to figure out what’s going on in those 50 lines of code. Raising the bar to 10 methods and 10 lines in each we get something like 150 lines and that should be on the edge of reasonableness.
Of course there are more sophisticated measures of code complexity, but even this simple strategy implemented as a compiler warning is a good start signal for a code cleanup. Way too often we detect bad parts of the code too late: when the source file is huge, the code is in production and sensitive to change and the responsibility for making the mess is diluted.
More clean code structure heuristics could be implemented in the clean code programming language. “Too many function arguments” is a code smell related to the dirty code structure. It is an easy one to detect and produce a warning if there are more than 3 function arguments. Yet another code smell “base classes depending on their derivatives” is also possible to detect and prohibit. Dead code as well can be detected and flagged for removal in most cases. When needed an exemption mechanism should allow you to describe dynamic interfaces of the code that seem to be unused at compile time, but will be used at runtime.

Clean error handling
From the clean code perspective Robert Martin recommends using exceptions instead of error codes, and specifically using “unchecked” exceptions. It means that any function can throw an exception. Feel free to handle it. I can recognize that the exception mechanism usage leads to cleaner “happy” code execution paths, and that unchecked exceptions reduce boilerplate code size because the error handling is only done when required and without extra declarations.
But to me this is an unfortunate place where clean code is in conflict with robust and safe code. If a function potentially throws an unchecked exception, it is easy to forget to catch it, and in result the whole program crashes (as in Null pointer exceptions hell). Usually one must put a “catch all” clause on the top of the call stack of each thread in order to at least log the error. This is where the entire context to recover is lost, so the app might have to crash anyway.
In my opinion each function or object should be responsible to deal with all possible scenarios of execution as much as possible either in place or by delegation. If the error condition is handled as soon as possible we have the full error context information, and there is the greatest chance to recover. Task execution is the function’s responsibility. It should only notify its upper management level about a failure if it is unable to recover or provide an alternative solution. Let’s imagine an example: we need to implement a network download. At some point we get disconnected. Yes, it is exceptional, but we can be prepared and handle this by waiting for the network to come back or doing a number of retries. On the low level the code is more complex, but also more robust. On the download manager level the code doesn’t deal with low level exceptions, it is treating downloads as long-running operations and displays the progress information including any encountered errors.
Go and Swift propose different approaches to error handling than unchecked exceptions. The errors in Go are just returned, but they are typed, and the caller code needs to check them. In Swift you have to specify the throws attribute and choose to either handle it or re-throw one level up the call stack. Also you have to put try keyword in order to call such function, so that there’s no surprise if a line of code can throw. In the clean code programming language static analysis can be used to detect places where the error might appear, but it was not checked or handled.
file, openError := os.Open("readme.dat")
buffer := make([]byte, 1024)
count, readError := file.Read(buffer)
"Warning: 'openError' is not checked!"
fmt.Printf("%d bytes read", count)
"Warning: 'readError' is not checked!"
Conclusions
The principles and heuristics of Clean Code were discovered and described many years ago in industrial programming, and a number of static analysis tools have emerged to partially deal with the problem and reduce the gap between casual programs and the clean code programs. Several programming languages were developed in the recent years with the best practices in mind, and yet a lot of practices stay unimplemented.
I hope that someday in upcoming 20 years we are going to have a clean code programming language that will incorporate more of the static analysis to help producing clean code software in a usual programming flow. This language is going to implement more of the best practices known today as described in this article, cultivating clean code style, clean naming and clean code structure.
| Subscribe to get more articles about programming languages | |
|
|
|
| Follow @battlmonstr |
|